注意:今天的文章與昨天的有連貫性喔,所以建議先去看 [Day-12] 解析 Spacy 的 Dependency Parsing
今天要繼續設計從 Spacy 的 Dependency Parsing 結果中,找出意見持有者、意見動詞、意見句子範圍的方法。也就是做出下圖中的效果。
昨天 [Day-12] 解析 Spacy 的 Dependency Parsing 的範例中,使用到以下程式碼片段來篩選出 Dependency Parsing 中的有用資訊:
if token.tag_ == 'VE':
subj = [w for w in chain(token.lefts, token.rights) if w.ent_type_ == "PERSON" or w.ent_type_ == "ORG"]
for s in subj:
print(f"{token}({token.tag_, token.ent_type_}) ---{s.dep_}---> {s}({s.tag_, s.ent_type_}) => {[t for t in s.subtree]}")
上方程式碼可以從以下範例文字的 Dependency Parsing 結果中,獲取上面程式碼規則所定義的目標資訊:
媒體關注數位部部長唐鳳對數位中介服務法看法,唐鳳表示,監理業務不屬於數位部範圍,面對大型跨境數位平台,最重要的是要確保現實世界中覺得合理的價值,平台上也應該符合相關的社會價值,遵守常規。
表示(('VE', '')) ---nsubj---> 唐(('Nb', 'PERSON')) => [唐, 鳳]
然而這樣單單使用條件(e.g. if)與迴圈(e.g. for)所組成的分析碼規,並不是最好的方式,之後當規則需要越來越複雜時,這樣的寫法容易導致更動困難與不易維護。所以今天就要來介紹更好的替代方案,那就是使用 Spacy 的 DependencyMatcher,這個做法後續還可以將找到的意見持有者、意見動詞、意見句子範圍做視覺化的標注呈現,超棒的!
等等會先使用到昨天的程式碼片段:
import stanza
import spacy_stanza
from ckip_transformers.nlp import CkipPosTagger, CkipNerChunker, CkipWordSegmenter
import spacy
from spacy import displacy
from itertools import chain
stanza.download("zh-hant")
nlp = spacy_stanza.load_pipeline("xx", lang='zh-hant')
def add_ner(doc):
ner_driver = CkipNerChunker(model="bert-base")
ner = ner_driver([str(doc)], show_progress=False)
ner_spans = []
for entity in ner[0]:
ner_spans.append(doc.char_span(entity.idx[0], entity.idx[1], label=entity.ner))
orig_ents = list(doc.ents)
doc.ents = orig_ents + ner_spans
def add_ckip_tag(doc):
pos_driver = CkipPosTagger(model="bert-base")
words = [[str(token) for token in doc]]
pos = pos_driver(words, show_progress=False)
for token, ckip_pos in zip(doc, pos[0]):
token.tag_ = ckip_pos
content = ['媒體關注數位部部長唐鳳對數位中介服務法看法,唐鳳表示,監理業務不屬於數位部範圍,面對大型跨境數位平台,最重要的是要確保現實世界中覺得合理的價值,平台上也應該符合相關的社會價值,遵守常規。',
'唐鳳今天中午接受震傳媒網路節目「新聞不芹菜」的視訊採訪,主持人黃光芹詢問唐鳳對於數位中介服務法(中介法)看法,是否反對立法。',
'唐鳳表示,中介法主要是監理非法言論部份,在數位部揭牌當天就提到,數位部的工作是扮演採油門角色,監理部份並不是數位部業務。',
'唐鳳直言,NCC日前提出數位中介服務法草案,還在NCC對外界徵詢草案的階段,目前NCC也提到會整理相關民間意見、歸零思考,把草案退回到工作小組。草案先前也還沒有提到政院討論,沒有要表態的問題。',
'唐鳳指出,面對跨境大型數位平台時,最重要價值是要確保現實社會覺得合理的價值,在大型數位平台上也應該符合相關的社會價值。',
'唐鳳舉例,監察院會公布競選期間政治獻金花費,選罷法也規範境外者不能給予候選人政治獻金,必須要符合透明度以及不能收國外的錢。前幾年有人透過數位平台下廣告、幫特定候選人打廣告,等於繞過政治獻金法的規範。',
'唐鳳指出,後來也有跟平台溝通,不管在美國是什麼樣的規範,在台灣就是要揭露、不能收國外的錢,不能到平台上就不遵守相關常規。平台後來在2019年做修正,舉這個例子是要說明,還是要從社會怎麼樣合適出發,這些跨境科技平台要配合社會價值,而不是擾亂社會價值、反過來要求配合平台。']
DependencyMatcher 的主要功能是讓使用者能透過自定義的 pattern 來在 Dependency Parsing 的結果中,找尋與 pattern 中規則對應的 Token。因此使用 DependencyMatcher 的第一步就是要根據需要的配對規則設計pattern。
以下是我設計的規則範例:
pattern 的 Python 程式碼如下:
pattern = [
{
"RIGHT_ID": "VE",
"RIGHT_ATTRS": {"TAG": "VE"}
},
{
"LEFT_ID": "VE",
"REL_OP": ">",
"RIGHT_ID": "who_root",
"RIGHT_ATTRS": {"DEP": "nsubj"}
},
{
"LEFT_ID": "VE",
"REL_OP": ">",
"RIGHT_ID": "idea_root",
"RIGHT_ATTRS": {"DEP": {"IN": ["ccomp", "parataxis"]}}
}
]
上面程式碼 pattern 中的三個 dict 照順序分別對應到我設計的三個歸則。
pattern的設計說明在 Dependency Matcher
先以 content 的第一段文字來演釋 match 使用:
doc = content[0]
add_ner(doc)
add_ckip_tag(doc)
content[0] 的文字內容是:
媒體關注數位部部長唐鳳對數位中介服務法看法,唐鳳表示,監理業務不屬於數位部範圍,面對大型跨境數位平台,最重要的是要確保現實世界中覺得合理的價值,平台上也應該符合相關的社會價值,遵守常規。
content[0] 的 Dependency Parsing 結果是: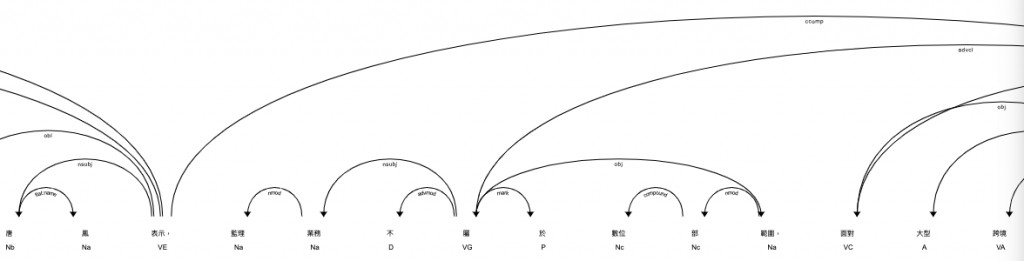
完整的樹狀結構請見此連結 中的第一個樹狀結構。
我設計了下方的程式碼來執行 match:
from spacy.matcher import DependencyMatcher
matcher = DependencyMatcher(nlp.vocab, validate=True)
matcher.add("Rule0", [pattern])
matches = matcher(doc)
matches_sorted = sorted(matches, key=lambda x: abs(x[1][0] - x[1][1]))
if len(matches_sorted) > 1:
matches_sorted = [match for match in matches_sorted if (match[1][0] == matches_sorted[0][1][0] and match[1][1] == matches_sorted[0][1][1])]
print(matches_sorted)
此段落 import DependencyMatcher 並建立 instance,再將前面定義的 pattern 加到 instance。
from spacy.matcher import DependencyMatcher
matcher = DependencyMatcher(nlp.vocab, validate=True)
matcher.add("Rule0", [pattern])
獲得 match 的初步結果:
matches = matcher(doc)
此時結果為 [(2992876933063962013, [16, 14, 36])],當中 [16, 14, 36] 依序代表了 pattern 中三個步驟所配對到的 Token index。也就是說
在特定情況會需要對 match 的結果進行後處理,本次範例如下:
matches_sorted = sorted(matches, key=lambda x: abs(x[1][0] - x[1][1]))
if len(matches_sorted) > 1:
matches_sorted = [match for match in matches_sorted if (match[1][0] == matches_sorted[0][1][0] and match[1][1] == matches_sorted[0][1][1])]
print(matches_sorted)
此段程式碼考量:
who_root 與 VE 配對的情況下,只選則who_root 與 VE 距離最近的配對結果。由於可以看到像是「唐(who_root)」或是「是(idea_root)」只是單一個 Token,需要配合其在 Dependency Parsing 結果中的子樹才能獲得完整資訊,所以要將 match 的結果以 span 的形式儲存在 doc:
if len(matches_sorted) > 0:
first_match = matches_sorted[0]
VE_id = first_match[1][0]
who_root_id = first_match[1][1]
VE_span = Span(doc, VE_id, VE_id+1, label="VE")
who_root_span = Span(doc, doc[who_root_id].left_edge.i, doc[who_root_id].right_edge.i+1, label="WHO")
idea_spans = []
for match in matches_sorted:
match_id, token_ids = match
idea_root_id = token_ids[2]
idea_spans.append(Span(doc, doc[idea_root_id].left_edge.i, doc[idea_root_id].right_edge.i+1, label="IDEA"))
doc.spans["sc"] = spacy.util.filter_spans([VE_span, who_root_span] + idea_spans)
for span in doc.spans["sc"]:
print(span.text, span.label_)
會得到以下輸出:
唐鳳 WHO
表示 VE
監理業務不屬於數位部範圍,面對大型跨境數位平台,最重要的是要確保現實世界中覺得合理的價值,平台上也應該符合相關的社會價值,遵守常規 IDEA
上面程式碼中的 spacy.util.filter_spans() 是為了過濾掉重複的 span。
最後使用下面程式碼即可將標註結果視覺化:
displacy.render(doc, style="span", jupyter=True)
示意圖如下:
以下為本次所設計的 pattern 所抓到具有標注的段落視覺化結果:
目前的 pattern 規則仍存在許多缺陷,還需要後續改進。
寫的有些匆忙,如果文章有錯誤,歡迎指正~

